This is a curious case that led me to discover and use a very valuable tool ANTS Profiler and read a few good blogs about .NET debugging and CLR internals. Read on to bookmark with me.
Near to Christmas we received a complain one of the windows applications was performing too slow after a few hours of usage. Performance monitor counters indicated the performance problem lied on high CPU peaks sustained for a long period of time.
.Net memory counters were somewhat fine, no increase on allocated bytes or overall memory consumption, no high IO reads, no high network usage…apparently the application was just doing its stuff, but for a long time, and each time longer…
First thing that came to our mind was an infinite loop, however the curious part on this case is that the CPU peaks took longer the longer the end user worked on the application and began to be noticeable after a couple of hours, not quite the definition of an infinite loop.
If only had we had a better CPU, had the performance downgrade been noticeable after more hours. This is something we had to be thankful for, bad CPU, less time to reproduce the problem. This was one of the typical production only problems too :-p
Long sustained CPU peaks, how we dug down on the cause:
First we grabbed the free debugging tools (insert the obvious reasons here, budget, management approval, etc): CLRProfiler, winDGB, SOS and ADPlus.
Two great blog posts about how to start with these tools can be found here (Speaking Of Which) and here (Maoni’s blog).
MSDN Magazine also has two good articles (Bugslayer column and this CLR Inside Out column) on the subject of windows debugging tools and how to use them in VS 2005.
Back to our own experience on the matter, CLRProfiler hung the machine beyond response and despite being able to sketch the object graph in memory, it was hard to correlate the time of the high CPU peaks with the information obtained from CLRProfiler.
This was not due to a problem with the tool itself, hanging was due to poor iron power and our over-consuming application and the inability to detect the main CPU usage cause was due to the fact that CLR profiler is only meant to identify and isolate problems related with garbage collection, excessive long lived objects or huge collections.
At first we thought the high CPU could be related with garbage collection due to long lived objects, see this post on Tess’s blog If broken it is, fix it you should.
We collected memory dumps with ADPlus during the high CPU peaks as per this lab blog post and analyzed the memory dumps using WinDBG.
At the end we decided to have more control on when the dumps were taken and use WinDBG while attaching it to the process. I should also mentioned ADPlus ended up generating dumps with errors when the system was really stressed.
Instructions to take dump via WinDBG :
1. Run the application.
2. Open up WinDBG. Click on File ?> Attach To Process ?> Select the process ?> Click on OK.
3. WinDBG attaches to the process and waits on the command line. Press ‘g’ and hit enter. ‘g’ is for letting the
application run.
4. Now whenever you want to take a dump, Hit Ctrl+Break in WinDBG. Now, type : .dump /ma C:\Dump1.dmp
This will take a dump.
5. Press ‘g’ and hit enter for the process to resume.
WinDBG can give valuable information about the CLR stack at the time the dump was collected (clrstack command), the types being scheduled for GC (!finalizequeue) and how many types marked for finalization belong to Gen 0, Gen 1 and Gen2.
Seeing your managed stack at a single point in time or having exact information about the memory allocation does not give information on the amount/% of CPU time each method takes though.
We tried taking dumps with WinDbg at the beginning of the CPU peak, in the middle and at the end but the results only offered a hint, too many Collections were allocated and lived to Gen 2. Some of this collections were byte arrays. It wasn’t apparent from analyzing the three managed stacks (from the three memory dumps) which method was consuming the longest time.


So far we had lots of collections surviving to Generation 2 and some of them were of type byte array. Garbage collection counters, however were within the “normal”.
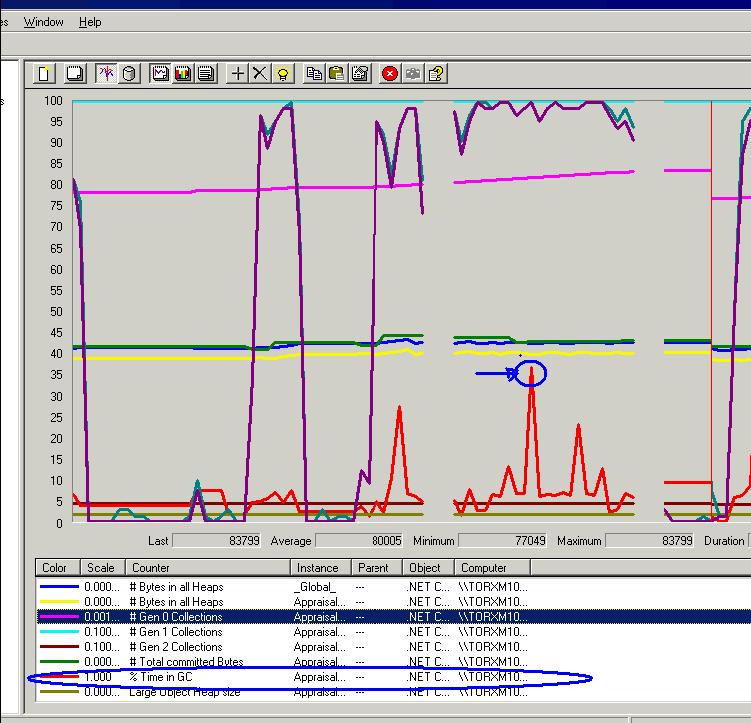
If the application was just “busy” doing its stuff, where was this time spent? Data Binding? Event Brokerage? Database access latency and query performance had been already discarded with SQL Profiler btw.
The main sustained CPU peak cause was discovered using ANTS profiler. Memory leaks, long GC cycles were discarded using the mentioned free tools.
ANTS profiler will let you set .NET performance counters and it will attach itself to the application being debugged. You cannot set breakpoints, afaik, but can go back in the profiler results and drag your cursor over a region to get a full called stack walk. It also goes beyond that and will indicate the % of time each method is taking on CPU and the % of time its children take on CPU usage.
Finally! A tool that will correlate performance counters the called stack for you and will indicate % of CPU time per method. This information you cannot gather by taking memory snapshots or called stack snapshots, unfortunately the free tools were only useful to discard memory leaks and GC related problems on this particular case. They narrowed down the places to look into.
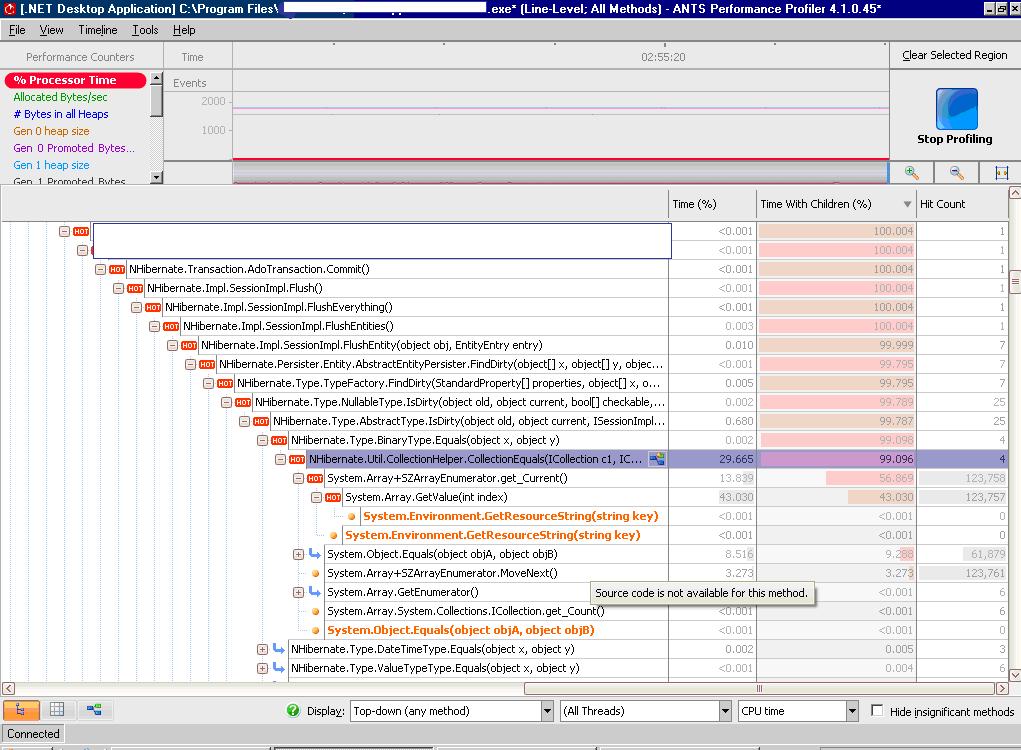
As you can see from the ANTS Profiler screen shot the application was indeed doing stuff, in this case comparing collections of bytes, byte per byte…Ouch!
We were able to identify the Collection comparison problem (byte[] arrays were being compared when the
NHibernate session was flushed and persisted even when they didn’t changed). We correlated this with a
fixed NHibernate bug:
http://jira.nhibernate.org/browse/NH-1246
and changed our mapping attributes to indicate there was no need to update the BinaryBlob fields. Our application either inserts the binary data or deletes its.
Note: you should be logged into http://jira.nhibernate.org/ before navigating to this bug report, registration is free.
Our NHibernate version and mapping strategy contained the buggy bits…
I hope this post hasn’t turned out too long, by upgrading NHibernate we solved the mystery of performance downgrade over time, the more the user worked with persistent binary data in the application the longer this loop comparing byte per byte on each collection took.
Upgrading NHibernate added to a performance challenge in another area, the application start up was taking longer. This will go on Part II as I should get some sleep.
Sweet dreams!
PS. VSTS 2008 has very promising capabilities for debugging high CPU usages, almost as good as ANTS Profiler, see this post
absolutely amazing, nice article!
Its an well written article with an important information regarding .net information.