Identifying performance bottlenecks on a .NET windows app. Part II Using Native Images with CAB, reviewing Fusion Logs
We left off on the previous post with a newer version of NHibernate and a different mapping that avoided the byte per byte comparison of our byte arrays, however our application start up was slower, about 20 seconds and showing some screens for the first time was taking 10 seconds, not acceptable.
The performance decrease was gone but the start up was not good enough.
We got our hands on ANTS profiler again to see what was going on whenever we invoked a screen for the first time:
CPU usage:
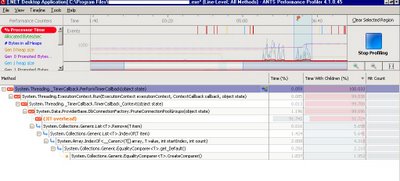
Jitted Bytes per second:

and IO Bytes Read:
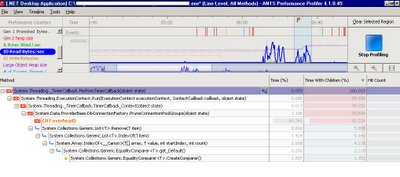
From these images we deducted there was quiet some Just-In-Time compilation going on when the screen was loaded. How to solve that? Using Native Images for our assemblies in order to avoid JIT compilation, see this MSDN article for this.
All in all that was quite easy to narrow down, we used NGen, installed the native images and voila!, let's profile again...
I wish it were that quick, we kept seeing JIT peaks :-O
Alright, let's use some heavier artillery and see why it's still JITting.
This is where we got our hands on Fusion logs. Fusion is the engine (DLL) in charge of loading and binding assemblies. The Fusion Log Viewer is the tool to see the logs for this DLL and troubleshoot loading problems. This tool is part of the SDK and can be downloaded from here. We aware that it's a heavy download. In order to use this tool once the SDK is installed:
1. Open in Fuslogvw.exe in folder C:\Program Files\Microsoft Visual Studio 8\SDK\v2.0\Bin
2. If it shows up any entry click on the list box click on Delete All.
3. Click on Settings and choose Log all binds to disk and check Enable custom log path
4. And in the Custom log path edit box type C:\FusionLog
5. In C: drive create a new folder and name it FusionLog
6. Now run the application and execute scenarios where we are seeing JIT-ing
7. Now when you browse to C:\FusionLog you would see couple of folders.
We were unable to install the SDK in our production clients, so we ended up doing a registry edit in order to collect the logs. If you don't want to install the SDK, do the following:
1) Go to regedit
2) HKEY_LOCAL_MACHINE\Software\Microsoft\Fusion
3) Click on the right pane and new -> string value
4) Name it LogPath,click it in the value write C:\MyLog
5) Again right click the right pane
6) go for new DWord value,name it ForceLog
7) click it and give Value "1"
8) Then create a folder in C drive with the name MyLogs
9) Run the app and logs will be created
The logs are created as HTM files in the folder you decide. reviewing our logs we found out one of our main modules wasn't loading from its native image although the native image was on the native image cache. Why?
Let's give some more background information, we use CAB.
The Composite UI Block from Patterns and Practices had a main release on December 2005, there's been other releases for WPF and the most recent Prism project, but apart from the Smart Client Factory addition, the CAB framework has stayed pretty much the same for Windows Forms.
CAB is known for its Module Loader Service and was highly welcomed by windows developers as a framework that allows loose coupling with it's Event Publishing/Subscription mechanism, it's Services module and its MVP implementation.
All that is very good for the developer and for maintainability but the performance is not the greatest if you have quite a few publications and subscriptions going on and if you have a few modules loaded at start up. There are quite a few posts regarding this on CodePlex's CAB forum.
I could go on and on about the beauty of CAB and despite its performance issues, I do believe it offers more advantages than disadvantages to the windows developer. IMHO, being able to give modules to develop to different teams and being able to plug them into the application without any major compilations, only a configuration change is a big big plus, see these posts on CAB Module Loader Service (CAB Modules on Demand) and Dynamically Loading Modules in CAB)
The main reason for this module not loading from its native image is due to the Reflection mechanism currently used in CAB's Module Loader Service:
(namespace Microsoft.Practices.CompositeUI.Services)
assembly = Assembly.LoadFrom(file.FullName);
More information on Cook's archives
Codeplex community member Mariano Converti was prompt on offering a solution on his blog.
How To: Use the Ngen tool to improve the performance in CAB / SCSF applications
As to the date of this post, this code change hasn't been incorporated into any CAB release, they should do it soon though.
Happy performance troubleshooting!
The performance decrease was gone but the start up was not good enough.
We got our hands on ANTS profiler again to see what was going on whenever we invoked a screen for the first time:
CPU usage:
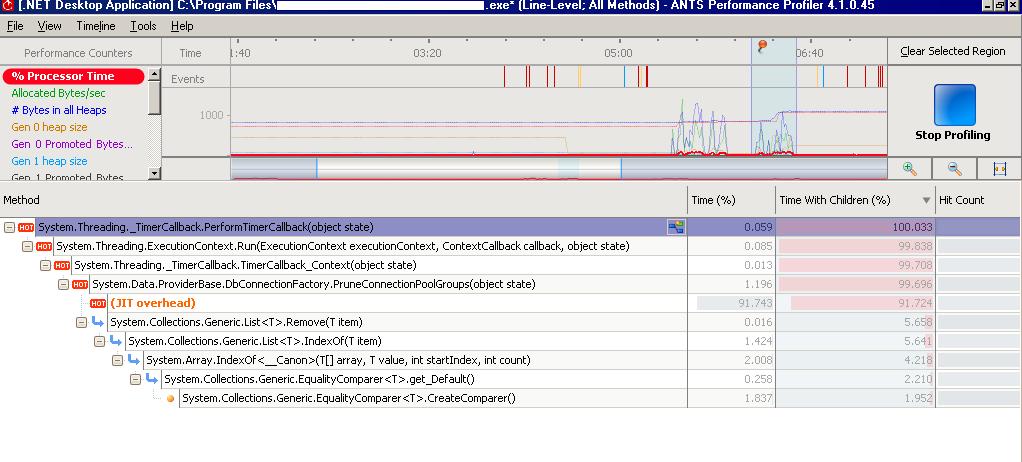
Jitted Bytes per second:
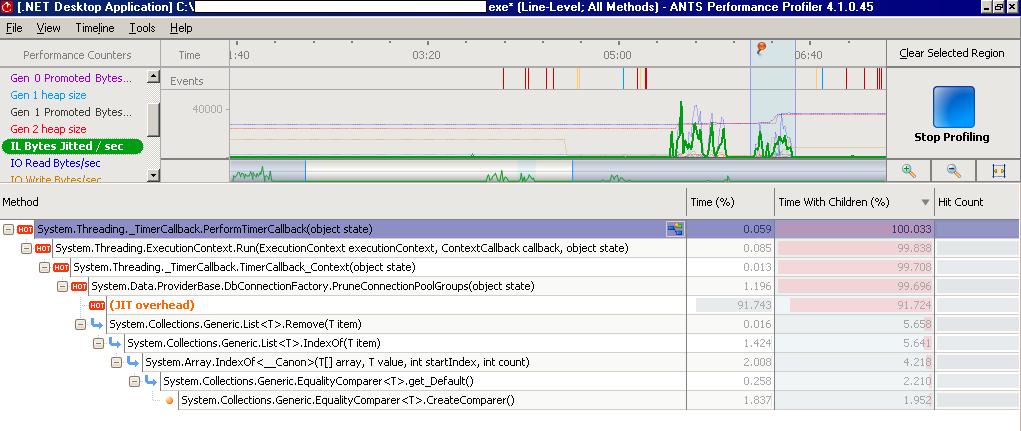
and IO Bytes Read:
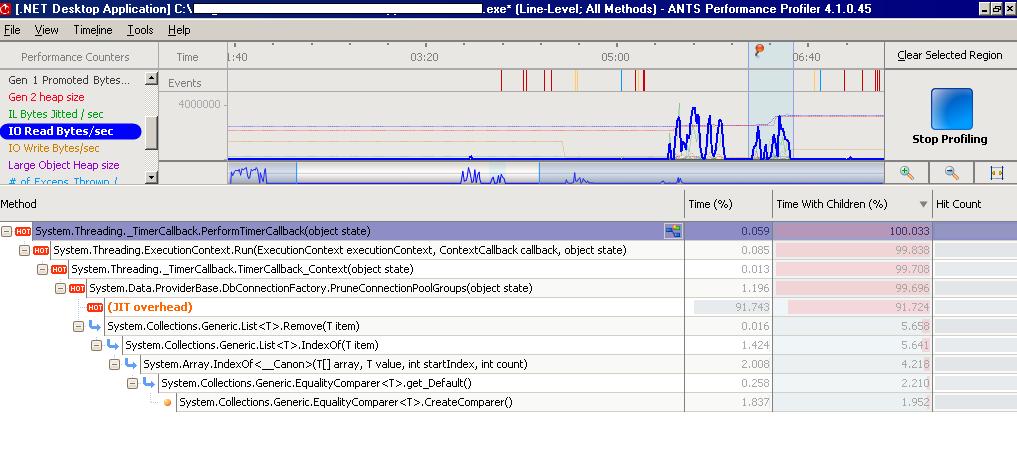
From these images we deducted there was quiet some Just-In-Time compilation going on when the screen was loaded. How to solve that? Using Native Images for our assemblies in order to avoid JIT compilation, see this MSDN article for this.
All in all that was quite easy to narrow down, we used NGen, installed the native images and voila!, let's profile again...
I wish it were that quick, we kept seeing JIT peaks :-O
Alright, let's use some heavier artillery and see why it's still JITting.
This is where we got our hands on Fusion logs. Fusion is the engine (DLL) in charge of loading and binding assemblies. The Fusion Log Viewer is the tool to see the logs for this DLL and troubleshoot loading problems. This tool is part of the SDK and can be downloaded from here. We aware that it's a heavy download. In order to use this tool once the SDK is installed:
1. Open in Fuslogvw.exe in folder C:\Program Files\Microsoft Visual Studio 8\SDK\v2.0\Bin
2. If it shows up any entry click on the list box click on Delete All.
3. Click on Settings and choose Log all binds to disk and check Enable custom log path
4. And in the Custom log path edit box type C:\FusionLog
5. In C: drive create a new folder and name it FusionLog
6. Now run the application and execute scenarios where we are seeing JIT-ing
7. Now when you browse to C:\FusionLog you would see couple of folders.
We were unable to install the SDK in our production clients, so we ended up doing a registry edit in order to collect the logs. If you don't want to install the SDK, do the following:
1) Go to regedit
2) HKEY_LOCAL_MACHINE\Software\Microsoft\Fusion
3) Click on the right pane and new -> string value
4) Name it LogPath,click it in the value write C:\MyLog
5) Again right click the right pane
6) go for new DWord value,name it ForceLog
7) click it and give Value "1"
8) Then create a folder in C drive with the name MyLogs
9) Run the app and logs will be created
The logs are created as HTM files in the folder you decide. reviewing our logs we found out one of our main modules wasn't loading from its native image although the native image was on the native image cache. Why?
Let's give some more background information, we use CAB.
The Composite UI Block from Patterns and Practices had a main release on December 2005, there's been other releases for WPF and the most recent Prism project, but apart from the Smart Client Factory addition, the CAB framework has stayed pretty much the same for Windows Forms.
CAB is known for its Module Loader Service and was highly welcomed by windows developers as a framework that allows loose coupling with it's Event Publishing/Subscription mechanism, it's Services module and its MVP implementation.
All that is very good for the developer and for maintainability but the performance is not the greatest if you have quite a few publications and subscriptions going on and if you have a few modules loaded at start up. There are quite a few posts regarding this on CodePlex's CAB forum.
I could go on and on about the beauty of CAB and despite its performance issues, I do believe it offers more advantages than disadvantages to the windows developer. IMHO, being able to give modules to develop to different teams and being able to plug them into the application without any major compilations, only a configuration change is a big big plus, see these posts on CAB Module Loader Service (CAB Modules on Demand) and Dynamically Loading Modules in CAB)
The main reason for this module not loading from its native image is due to the Reflection mechanism currently used in CAB's Module Loader Service:
(namespace Microsoft.Practices.CompositeUI.Services)
assembly = Assembly.LoadFrom(file.FullName);
More information on Cook's archives
Codeplex community member Mariano Converti was prompt on offering a solution on his blog.
How To: Use the Ngen tool to improve the performance in CAB / SCSF applications
As to the date of this post, this code change hasn't been incorporated into any CAB release, they should do it soon though.
Happy performance troubleshooting!
Labels: .NET 2.0, ANTS Profiler, CAB, CLR, Fusion, Performance
posted by Lizet Pena de Sola at
9:49 AM
0 Comments
![]()
![]()
