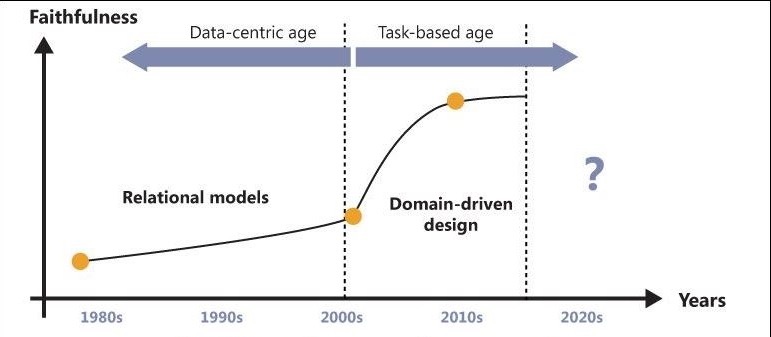
The following paragraphs in italic are taken from an article in IASA (International Association of Software Architects) written by Gene Hughson
In spite of all that’s been written on the subject of technical debt, it’s still a common occurrence to see it defined as simply “bad code”. Likewise, it’s still common to see the solution offered being “stop writing bad code”. It’s not that simple.
What is Technical Debt?
A design or construction approach that’s expedient in the short term but that creates a technical context in which the same work will cost more to do later than it would cost to do now (including increased cost over time) .
Technical debt may not only incur costs due to rework of the original item, but also by making more difficult changes that are dependent on the original item.
Deferring bug fixes is a form of technical debt as is deferring automation of recurring support tasks.
Dependencies can be a source of technical debt, both in regard to debt they carry and in terms of their fitness to your purpose.
The platform that hosts your application is yet another potential source of technical debt if not maintained.
As noted above, the “interest” on technical debt can manifest as the need for rework and/or more effort in implementing changes over time. This increase in effort can come through the proliferation of code to compensate for the effects of unresolved debt or even just through increased time to comprehend the existing code base prior to attempting a change.
In short, technical debt is any technical deficit that involves a risk of greater cost to expand the application and/or end user dissatisfaction.
What to do about it?
Becoming aware of existing debt is a critical first step, but is insufficient in itself. Taking steps to actively manage the system’s debt portfolio is essential. The first step should be to stop unconsciously taking on new debt. Latent debt tends to fit into the immediate, unexpected payback model mentioned above. Likewise, steps taken to improve the quality up front (unit testing, code review, static analysis, process changes, etc.) should reduce the effort needed for detection and remediation. Architectural and design practices should also be examined. Too little design can be as counter-productive as too much.
Just as the taking on of new debt should be done in a rational manner, so should be the retirement of old debt.
Think of technical debt as credit card debt and you’ll realize why it is important to account for it, be aware of it and pay it off before funding any new features.