I got the following email from devx.com, unfortunately when I replied to this colleague, the email bounced. I’m hoping he can Google this up.
Hi Lizet,
I just read your article on www.devx.com about data loss in Merge Replication. Unfortunately we are experiencing this exact same bug. I have already upgraded the subscriber server to SP3. Do you know if the fix for this issue is included in SQL Server Express SP3 and will it get applied if I just upgrade an existing instance from SP2 to SP3? Or do I need to do a complete uninstall and reinstall? Also, is there anything I can do to verify the subscriber instance had the correct patches applied to it? I appreciate your help on this and the article you wrote. We have a lot of work ahead of us restoring data lost but it could have been worse if not for this article.
I appreciate your time.
My replies:
As far as I can remember any SQL Server Engine (whether Express or Standard or Enterprise) had the problem.
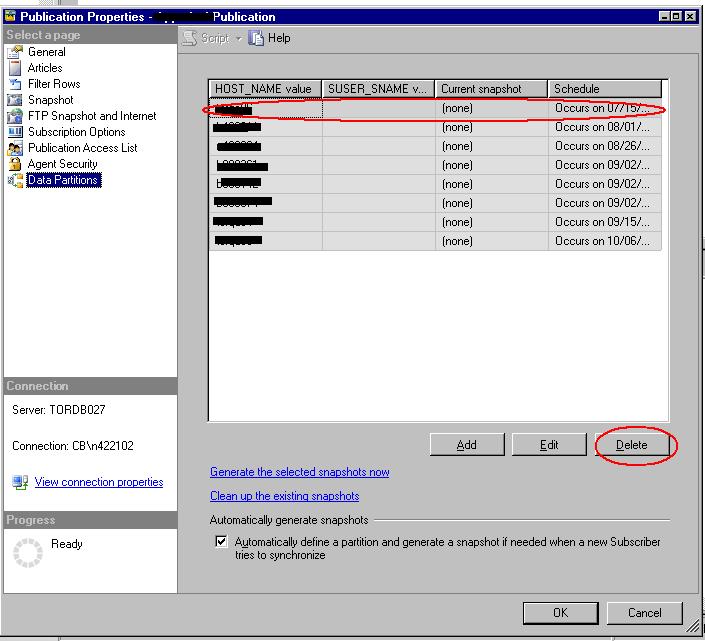
The publisher and the distributor (which can only be a Standard or an Express instance) should be patched as well. Any engine with a version lower than 9.00.3228.00 should be patched, whether applying SP3 or only the Cumulative Update they launched after the replication problem came to the public light.
You can check the version at the subscribers using sqlcmd.
If your subscriber engines are installed as the default engine and use windows authentication, you can connect to them using the following command, you need to be an administrator on the machine in order to apply the CU:
sqlcmd -E
checking the version on the sqlcmd command prompt would be:
> select @@version
>GO
I remember patching the subscribers was a pain, as we didn’t want to push the update automatically and we connected to every single subscriber remotely to make sure the patch (CU6 for SP2 in our case) was applied properly.
I added a post to my blog with the line of code that caused the mess. The link is
Hope this helps, good luck
and
I forgot to answer two of your questions:
Do you know if the fix for this issue is included in SQL Server Express SP3
Yes, the fix is included in SP3. Make sure you patch the publisher and distributor as well, not only the subscribers.
and will it get applied if I just upgrade an existing instance from SP2 to SP3?
Yes.
Or do I need to do a complete uninstall and reinstall?
No, just patch.
Usually you can recover the published database from a previous backup but as you usually don’t keep synchronized backups of each subscriber, you have to recreate the publication and subscriptions, potentially destroying any data at the subscribers that has not been merged yet. Or you could copy the subscriber database to a different location, recreate publication and subscription and manually add the data that didn’t merge from your saved database to the newly merged database.
Hopefully this reaches you, again good luck recovering the data.