The initial post for Part I – HTTP Secure is here.
I got a question right after I had spent a week in training classes for the COMPTIA Security+ exam: to describe how HTTP Secure (HTTPS) modifies the HTTP traffic between a client browser and the server.
At the end of my explanation, this person also asked me what was the role of Diffie-Hellman algorithm in the whole process.
I was almost sure that Diffie-Hellman isn’t used all the time in HTTPS but I didn’t know how to explain, on the spot, when is Diffie-Hellman actually used. The person asking me the question was part of a review board and was adamant that Diffie-Hellman was always used.
I’ll abbreviate Diffie-Hellman as D-H for the remaining of this post.
How is the HTTP traffic between a server and a client modified when the channel is encrypted? What is SSL?
What is the role of the D-H key exchange algorithm?
Is D-H always used in HTTPS?
Those are the questions I’ll try to answer on this post.
How is the HTTP traffic between a server and a client modified when the channel is encrypted?
Similar to an HTTP request, the client begins the process by requesting an HTTPS session. This could be by entering an HTTPS address in the URL or by clicking on an HTTPS hyperlink. Now, when the link must be secured the server responds by sending the server’s certificate. The certificate includes the server’s public key. The matching private key is on the server and only accessible by the server. The client then creates a symmetric key and encrypts it with the server’s public key. The creation of the symmetric session key is what differs in the different versions of SSL and could use D-H in some cases for the generation of the exact same key by the client and the server, so the key is never actually exchanged. This symmetric key (also called ephemeral key or session key) will be used to encrypt data in the HTTPS session. When D-H is not used, the client sends the encrypted session key it generated to the web server. This key is encrypted using the server’s public key. Only the server’s private key can decrypt the cypher and obtain the client’s session key. If attackers intercept the encrypted key, they won’t be able to decrypt it since they don’t have access to the server’s private key. The server receives the encrypted session key and decrypts it with the server’s private key, this is not true when D-H is used though, as the server generates an identical session key as the one that was generated by the client. At this point, both the client and the server know the symmetric/session key. All of the session data exchanged over the link is encrypted with this symmetric/session key using symmetric encryption.
In the case the server is configured to accept client certificates to authenticate the client, the exchange differs a little from the one described above. Digital certificates provide a way for the clients to trust the server with validations that can be done of the certificate presented by the server, but this subject (client certificates involved on the HTTPS exchange and server authentication using digital certificates) is beyond the scope of this post.
What is SSL?
SSL Secure Sockets Layer (SSL) is an encryption protocol used to encrypt Internet traffic. For example, HTTPS uses SSL in secure web browser sessions. It can also encrypt other transmissions. For example, File Transport Protocol Secure (FTPS) uses SSL to encrypt transmissions. SSL provides certificate-based authentication and encrypts data with a combination of both symmetric and asymmetric encryption during a session. It uses asymmetric encryption to privately share a session key, and symmetric encryption to encrypt data displayed on the web page and transmitted during the session. Netscape created SSL for its web browser and updated it to version SSL 3.0. The IETF created TLS to standardize improvements with SSL. TLS Transport Layer Security (TLS) is a replacement for SSL and is widely used in many different applications. The IETF has updated and published several TLS documents specifying the standard. TLS 1.0 was based on SSL 3.0 and is referred to as SSL 3.1. Similarly, each update to TLS indicated it was an update to SSL. For example, TLS 1.1 is called SSL 3.2 and TLS 1.2 is called SSL 3.3.
SSL keeps the communication path open until one of the parties requests to end the session. The session is usually ended when the client sends the server a FIN packet, which is an indication to close out the channel. SSL requires an SSL-enabled server and browser. SSL provides security for the connection but does not offer security for the data once received. In the protocol stack, SSL lies beneath the application layer and above the network layer. This ensures SSL is not limited to specific application protocols and can still use the communication transport standards of the Internet. Different books and technical resources place SSL at different layers of the OSI model, which may seem confusing at first. But the OSI model is a conceptual construct that attempts to describe the reality of networking. The SSL protocol works at the transport layer. Although SSL is almost always used with HTTP, it can also be used with other types of protocols. So if you see a common protocol that is followed by an s, that protocol is using SSL to encrypt its data. SSL is currently at version 3.0. Since SSL was developed by Netscape, it is not an open-community protocol. This means the technology community cannot easily extend SSL to interoperate and expand in its functionality. If a protocol is proprietary in nature, as SSL is, the technology community cannot directly change its specifications and functionality. If the protocol is an open-community protocol, then its specifications can be modified by individuals within the community to expand what it can do and what technologies it can work with. So the open-community version of SSL is Transport Layer Security (TLS). The differences between SSL 3.0 and TLS is slight, but TLS is more extensible and is backward compatible with SSL.
The most complex part of SSL is the Handshake Protocol. This protocol allows the server and client to authenticate each other and to negotiate an encryption and Message Authentication Code (MAC) algorithm and cryptographic keys to be used to protect data sent in an SSL record. The Handshake Protocol is used before any application data is transmitted. The Handshake Protocol consists of a series of messages exchanged by the client and the server.
The Figure below shows the initial exchange needed to establish a logical connection between the client and the server. The exchange can be viewed as having four phases.
Handshake Protocol in Action 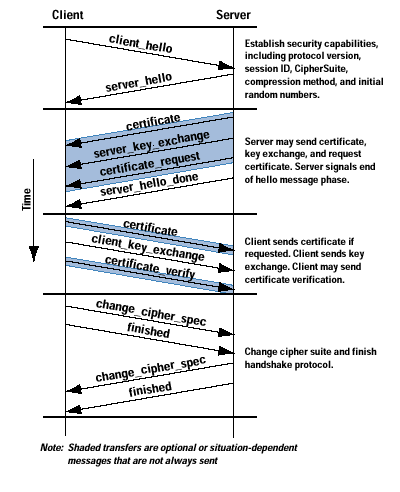
After sending the client_hello message, the client waits for the server_hello message, which contains the same parameters as the client_hello message. For the server_hello message, the following conventions apply. The Version field contains the lower of the version suggested by the client and the highest version supported by the server. The Random field is generated by the server and is independent of the client’s Random field. If the SessionID field of the client was nonzero, the same value is used by the server; otherwise the server’s SessionID field contains the value for a new session. The CipherSuite field contains the single CipherSuite selected by the server from those proposed by the client. The Compression field contains the compression method selected by the server from those proposed by the client.
What is the role of the D-H key exchange algorithm?
D-H is a key exchange algorithm used to privately share a symmetric key between two parties, it wasn’t deviced in the context of digital certificates and pre-dates them. The Diffie-Hellman scheme was first published in 1976 by Whitfield Diffie and Martin Hellman. The idea of D-H is that it’s easy to compute powers modulo a prime but hard to reverse the process: If someone asks which power of 2 modulo 11 is 7 , you’d have to experiment a bit to answer, even though 11 is a small prime. If you use a huge prime istead, then this becomes a very difficult problem
The D-H algorithm enables two systems to exchange a symmetric key securely without requiring a previous relationship or prior arrangements. The algorithm allows for key distribution, but does not provide encryption or digital signature functionality. The algorithm is based on the difficulty of calculating discrete logarithms in a finite field. The original Diffie-Hellman algorithm is vulnerable to a man-in-the-middle attack, because no authentication occurs before public keys are exchanged.
Is D-H always used in HTTPS?
The answer is NO. In practice, Diffie–Hellman is not used with RSA being the dominant public key algorithm.
The first element of the CipherSuite parameter (see the Handshake Protocol in Action figure above) is the key exchange method. The following key exchange methods are supported on HTTP Secure:
RSA: The secret key is encrypted with the receiver’s RSA public key. A public-key certificate for the receiver’s key must be made available.
Fixed Diffie-Hellman: This a Diffie-Hellman key exchange in which the server’s certificate contains the Diffie-Hellman public parameters signed by the certificate authority (CA). That is, the public-key certificate contains the Diffie-Hellman public-key parameters. The client provides its Diffie-Hellman public key parameters either in a certificate, if client authentication is required, or in a key exchange message. This method results in a fixed secret key between two peers, based on the Diffie-Hellman calculation using the fixed public keys.
Ephemeral Diffie-Hellman: This technique is used to create ephemeral (temporary, one-time) secret keys. In this case, the Diffie-Hellman public keys are exchanged, and signed using the sender’s private RSA or DSS key. The receiver can use the corresponding public key to verify the signature. Certificates are used to authenticate the public keys. This option appears to be the most secure of the three Diffie-Hellman options because it results in a temporary, authenticated key.
Anonymous Diffie-Hellman: The base Diffie-Hellman algorithm is used, with no authentication. That is, each side sends its public Diffie-Hellman parameters to the other, with no authentication. This approach is vulnerable to man-in-the-middle attacks, in which the attacker conducts anonymous Diffie-Hellman exchanges with both parties.
References:
Harris, Shon. CISSP All-in-One Exam Guide, Fifth Edition (Kindle Locations 16125-16152). McGraw-Hill.
SSL: Foundation for Web Security – The Internet Protocol Journal – Volume 1, No. 1
Gibson, Darril. CompTIA Security+: Get Certified Get Ahead: SY0-301 Study Guide
The Secure Sockets Layer Protocol
HTTP over TLS
Diffie Hellman Key Agreement Method.